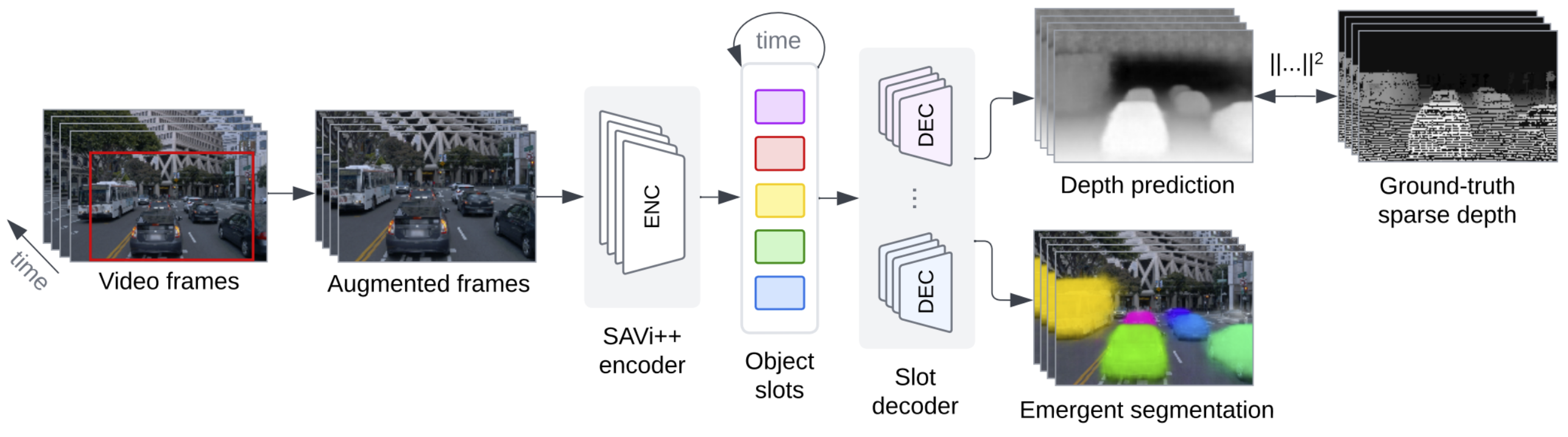
Figure: SAVi++ model for self-supervised decomposition of real-world driving video.
SAVi++ is an object-centric video model based on Slot Attention for Video (SAVi), which encodes a video into a set of temporally-consistent latent variables (object slots). Objects are discovered, tracked, and segmented solely via the inductive bias of the slot-based architecture or alternatively with the help of bounding box cues in the first video frame. By utilizing sparse depth signals obtained from LiDAR as a self-supervision target, data augmentation, and architectural improvements, SAVi++ is able to — unlike prior methods — scale to complex real-world driving scenes from the Waymo Open dataset. We further find that these improvements allow SAVi++ to address video decomposition in challenging synthetic multi-object video benchmark datasets (MOVi) with complex, diverse backgrounds, moving cameras, and diverse objects, which prior methods failed to decompose.
Qualitative Results on Waymo Open
When conditioned on bounding boxes in the first frame, SAVi++ is able to segment and track large objects in the scene until they leave the field of view. At this point the slot typically latches on to another object in the scene.
Figure: SAVi++ results on Waymo Open conditioned on bounding boxes in the first frame.
Like SAVi, SAVi++ can also be run without any conditioning cues in the first frame using randomly sampled slot initializations. We find that unconditioned (fully unsupervised) decomposition partially works on the Waymo Open dataset, although tracking consistency is lower than in the conditional case. As shown below, slots latch onto, for example, various street side objects and passing vehicles.
Figure: Unconditional SAVi++ model results on Waymo Open.
Reference
@inproceedings{elsayed2022savipp, author = {Elsayed, Gamaleldin F. and Mahendran, Aravindh and van Steenkiste, Sjoerd and Greff, Klaus and Mozer, Michael C. and Kipf, Thomas}, title = {{SAVi++}: Towards end-to-end object-centric learning from real-world videos}, booktitle = {Advances in Neural Information Processing Systems}, year = {2022} }